
教育背景
专业课程
竞赛奖项 :全国大学生统计建模大赛省级(北京市)一等奖、WorldQuant 量化投资大赛金牌
其他奖项 :校级竞赛类奖学金、思源宣讲团宣讲比赛院级一等奖、军训板报比赛校级二等奖
实习经历
实习概述:参与 OECD 支柱二全球最低税合规项目,服务中粮集团、太平洋保险、中国信达、长城汽车等多家大型企业客户,独立承担实体股权架构分析、基础信息表编制、公司名称翻译及财务数据汇总等数据全流程工作
工具开发:主导中粮集团 1,258 家实体的股权结构数据清洗,面对大量公司名称前后不一致导致 Excel 公式无法自动匹配的问题,自主开发 Python 模糊匹配程序,基于字符串相似度算法实现实体名称自动比对与分级归类,生成匹配报告交付团队与客户确认。基于上述数据处理痛点,进一步开发通用型 Excel 标准化工具(支持大小写统一、空格规范化、CJK 字符清洗),两种工具均以 Flask 构建 Web 界面并开源至 GitHub,形成可复用的工具化解决方案 NameLink Excel-Standardizer
股权穿透:负责太平洋保险集团近 200 家实际控制企业的股权穿透分析,综合运用启信宝、天眼查等企业信息平台进行交叉验证,梳理多层嵌套股权架构,输出并表所需的标准化股权结构信息
授信分析:参与企业授信报告编写与财务尽调工作,运用企查查等平台采集目标企业工商信息、股权结构等数据;深入分析客户财务报表,运用 Excel 构建信用评分模型,结合多种图表分析方法,从偿债能力(流动比率、速动比率)等多维度量化评估企业信用风险,为信贷审批决策提供数据支撑。
业务管理:协助完成对公业务全流程管理,整理汇总外汇业务等 12 类高频业务咨询记录,建立标准化知识体系;参与企业银行账户开户流程,协助审核企业营业执照等开户资料,熟悉外汇业务登记、询证函办理等业务流程。
毛利对标:参与某项目的跨单位毛利率对标分析,运用 Excel 处理所属施工单位在系统内外主要市场的经营数据;通过横纵向对比分析近年毛利率变化趋势,识别各单位市场竞争优势,为项目投标策略优化提供数据支撑。
风控建模:协助搭建两套财务风控模型并完善可视化分析工作:①合同资产质量评价模型:抽取 190 余个项目的新增合同资产样本,从收入结算及时性得分、超合同额确认风险得分、项目完工状态得分三大维度构建加权综合评分体系;运用 Excel 进行数据清洗并计算新增合同资产质量综合得分,精准识别 35 个超合同额项目风险敞口;②市场质量分析模型:整合 21 个细分市场共 4,000 余个项目数据,从项目毛利率等关键指标进行多维量化分析;建立横向单位间对标、纵向 5 年趋势分析的双向评价机制,成功识别高风险市场领域,为优化新签合同布局提供决策依据。
论文发表
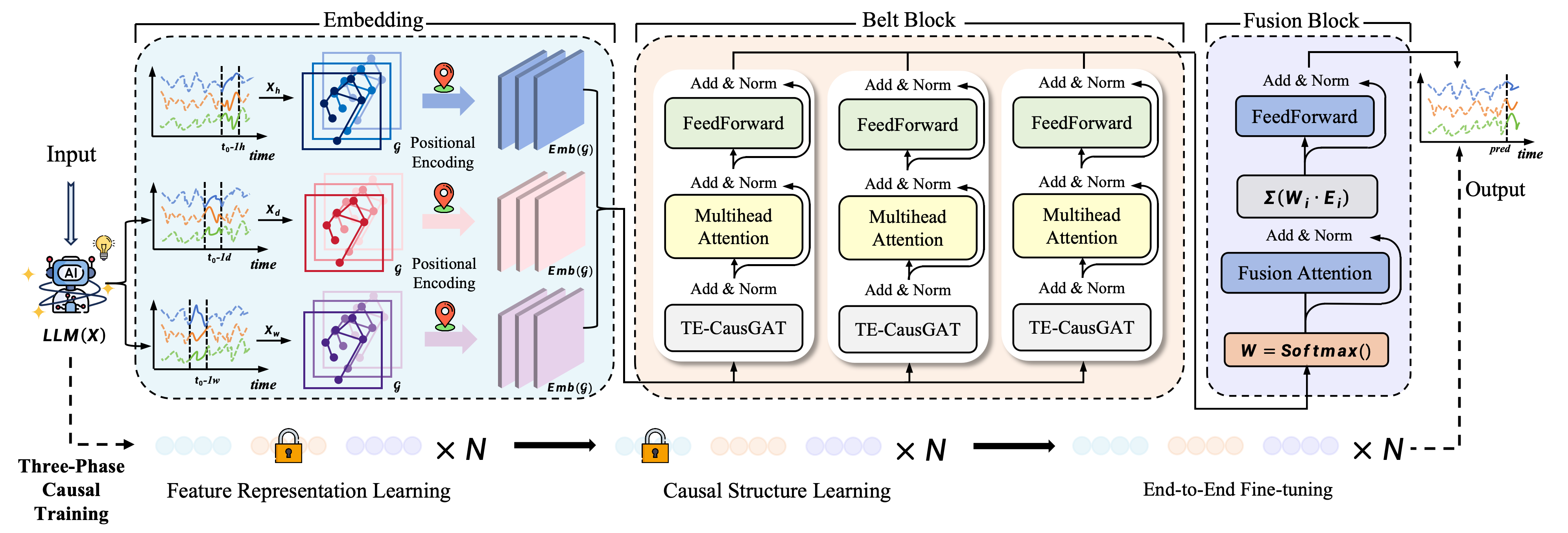
问题切入:现有时空 GNN 依赖对称邻接矩阵,无法区分"谁影响谁",交通事故沿 A→B→C 单向传播拥堵,对称图却错误赋予 C→A 权重;且已有图学习方法缺乏机制验证学到的边权是否具有预测意义而非虚假相关。
方法设计:提出 Orion 框架,核心 TE-CausGAT 模块基于 Granger 因果原理分段估计时变有向依赖矩阵,通过贝叶斯融合整合学习结构与先验邻接;首创预测一致性自验证——对节点 i 执行 mask 干预后测量节点 j 预测变化Δŷ_j,要求其与边权 C_{ij} 一致,训练中自动过滤未通过干预测试的虚假边。架构上 Belt Block 并行建模小时/日/周三尺度,三阶段渐进训练避免联合优化的局部最优。
实验结果:5 个基准上取得 SOTA:METR-LA MAE 降低 6.60%,PEMS-08 降低 8.65%,流行病数据 CA/TX 分别降低 22.70% 和 37.73%。DREAM-3 基因调控网络有向图发现 AUC 达 0.6295,超越最强基线 CUTS 6.42%,验证所学结构与 ground-truth 因果关系的一致性
项目经历
系统架构:基于 Claude Code 的 Skill 机制,独立设计了一套模块化的 Prompt Engineering Pipeline。以 SKILL.md 为主控调度文件,串联题目解读、作文修改、网页生成三个独立提示词模块,配合雅思官方评分标准与高分范文语料库,构成完整技能包。用户只需将题目和原文放入指定目录,一条指令即可触发 Agent 自动执行完整的八步工作流。
评审流程:核心理念是构建个人定制化学习库而非通用批改工具。Agent 依次完成"学习评分标准→学习范文语料→解读题目→阅读原文→评审修改→生成文件→更新网页→交付成果"八步流程;修改策略采用"语法纠正→词汇提升→句式优化→内容建议"四级渐进机制,保留原文结构前提下精准提升,每处修改标注类型与理由;评分对接雅思官方实现四维度(TR/CC/LR/GRA)打分与前后对比,结合个人写作习惯与语料库生成可复用模板句式,兼顾评审精度与教学实用性。
产出与扩展:系统自动生成并增量更新个人学习网站(主页、写作模板页、好词好句页等),支持修改过程可视化、多视图切换与分类筛选等交互功能,并通过 GitHub Pages 部署实现手机电脑多端同步访问。在大作文批改系统成熟后,通过 Bootstrapping 将整套 Pipeline 平滑扩展至小作文评审,验证了模块化 Prompt 架构的可扩展性。 Task 2 学习网站 Task 1 学习网站
舆情采集:复现并优化开源爬虫 EastMoney_Crawler,使用 Selenium 模拟浏览器访问东方财富股吧,结合 CSS 选择器提取帖子标题、浏览量、发帖时间等字段,配合随机延时与 stealth.js 反检测注入规避反爬;数据落盘 MongoDB,共采集国航、东航、南航三家公司 2.5 万条全年舆情数据,清洗后输出标准化 CSV
情感分析:构建两套评分方案并系统对比——①CFSD 金融词典在 Excel 中通过 LEN/SUBSTITUTE 统计正负词频计算归一化得分;②FinBERT(bert-base-chinese 金融微调)使用 T4 GPU 批量推理提取三分类概率计算连续得分。通过 6 组典型案例定量论证 FinBERT 在否定句式、反讽及隐含情感场景下的优越性(如"恐慌时反着来"词典误判 25 分、FinBERT 正确识别 58.64 分),最终采用 FinBERT 得分纳入评价体系。
综合评价:参与构建"财务三维+舆情+ESG"五维竞争力模型,采用 Min-Max 标准化与多组权重稳健性检验,量化三大航在资源、运营、适配、市场感知及可持续发展维度的结构性差异。
WorldQuant 量化投资大赛:大赛聚焦 Alpha 因子挖掘与优化。开发 10 余个高质量因子(Sharpe≥1.25,换手率≤70%),涵盖价量特征、财务指标、另类数据等维度。通过特征工程优化信号质量,控制交易成本。目前累计得分 19,538,全球排名前 5%,获得大赛金牌与 WorldQuant 量化顾问资格。
因子验证与多因子模型构建:筛选表现优异因子(Sharpe≥2.0)迁移至 A 股市场,使用 Tushare 获取全市场历史数据,搭建标准化单因子检验框架(含收益率分析、IC/IR 计算、分层回测等),验证因子有效性;整合 Sharpe≥1.0 的优质因子,基于 2018 年至今 A 股数据,构建 XGBoost/LightGBM 集成学习模型,实现因子非线性融合。
舆情采集:基于 Selenium 与 ChromeDriver 搭建微博关键词语料自动化采集管线,采用 7 日滑动时间窗口分段策略规避搜索接口分页上限,通过 XPath 结构化抽取发布人、时间及正文字段,累计采集数万条语料并以 Excel 格式交付,支撑后续文本挖掘与情感分析建模。
技术创新:提出面向交通流量预测的深度学习模型,设计基于 KNN 的动态图注意力网络与多头自注意力融合模块,构建三周期输入及权重约束机制捕捉多尺度时空依赖;该工作为后续 KDD 2026 投稿论文 Orion 框架奠定了基础。 Code
实验验证:带领团队处理 PeMS 等 5 个大规模交通数据集(1000+ 监测点、10 万+ 时间步),预测 MAE 较基线降低 15–30%,长期预测误差增长率降低 50%;斩获北京市省级一等奖。
工具开发:独立设计并开发一款 Excel 多语翻译工具(Python 5000+ LOC),集成 DeepSeek、Claude 等 5 种翻译引擎,实现单元格内容智能分类(公式/数字/URL 等自动跳过)、JSON 批量翻译、断点续传与指数退避重试机制;基于 Flask + SSE 构建 Web 可视化界面,支持实时进度推送、双语对照翻译报告生成。目前程序已开源至 GitHub ExcelTranslator-Pro
技术方案:使用网络爬虫构建新数据集并设计创新多模态 Transformers 架构。融合预训练 BERT 处理新闻文本,采用多头注意力机制处理六大股价技术指标;通过优化 Encoder-Decoder 结构增强模型的长期依赖捕捉能力。
项目成果:独立完成模型开发,初步实验预测精度显著优于传统模型;正进行超参数优化,目标高水平会议论文。
实践经历
内容设计:深入研究"自指问题"的理论内涵与现实意义,查阅 20+ 篇相关文献资料,设计 15 分钟的宣讲内容,创新性地将抽象概念与生活实例相结合,同时阐述了对人工智能的深入思考,在学院思源宣讲比赛中斩获一等奖(前 5%)。
实践综述:制定多渠道获客方案,在天坛公园等热门景区设立固定拍摄点位与个人定制路线,独立完成从客户需求分析到后期修图全流程;2 个月内实现营业收入 2 万元,积累优质作品 500+ 张,客户好评率达 98%。
摄影执行:负责校级运动会、各类表彰大会等 30+ 场活动拍摄;熟练掌握 LR、PS 等工具,形成标准化工作流程
技能 / 兴趣
语言技能
雅思 6.5 分、六级 513 分、国际人才英语考试(中级)取得"良好"成绩
编程与数据分析
Python(Pandas / NumPy / PyTorch / Scikit-learn)、R、SQL、C语言;熟悉时序与图结构数据建模,能独立搭建从数据清洗、特征工程到模型调优的端到端 ML Pipeline。
工具与平台
LaTeX、SPSS、EViews;MS Office(已通过计算机二级考试);能熟练使用 Claude Code、GitHub Copilot 等 AI 辅助开发工具链,掌握 Prompt Engineering 与 AI Agent 工作流,具备 OpenClaw 等开源 Agent 的部署与 Skills 开发经验;同时具备 Vibe Coding 能力,可快速将创新想法落地为可运行原型,显著提升数据处理与开发效率。